ConvNet => ViT
Random Initialized Network + Task Specific Training => Pretraining + Task Specific Training
과연 유사한 Pre-training 조건에서도 ConvNet보다 ViT가 우세할까?
NFNet F7+ (F7 보다 Width가 더 넓은)를 Compute vs. Val Loss로 테스트한 결과 Compute budget에 따라 Optimal model size와 epoch budget (데이터의 양)이 증가함을 확인.
즉, Transformer에서와 유사한 Scaling pattern을 확인했다.
결과적으로 ImageNet Top-1 90.3%의 정확도를 얻었음
이는 이전에 NFNet F5 (RA)를 통해 달성했던 86.8%의 ImageNet 결과를 크게 앞서는 결과임
정리
Pre-train의 Compute Resource를 유사한 수준으로 사용할 경우
ConvNet도 ViT와 유사한 수준의 성능을 보인다.
즉, Scaling Law는 Transformer라는 특정 아키텍처에서만 적용되는 것이 아닌 ConvNet 등에서도 적용될 수 있는 현상이며
따라서 Transformer를 고집할 필요 없다.
MoE 아키텍처는 sparse routing을 통해 높은 accuracy를 보이면서도 더 빠른 추론을 제공
하지만 이를 효과적으로 운영하기 위해서는 3.2TB의 GPU 메모리가 필요하며 Deploy를 어렵게 하는 요인임
새로운 압축 방식인 QMoE를 통해 Parmeter당 1-bit 이하의 크기로 압축
큰 정확도의 손실 없이 1.6T param 모델을 160GB의 메모리만으로 운영할 수 있도록 함
Approach - Data-dependent Quantization
Qauntization 즉, 정밀도를 감소시키는 방법이 널리 효과적
특히 대규모 모델의 경우 단순한 rounding만으로 precision을 효과적으로 감소 시킬 수 있음. 이를 통해 8bit 심지어는 4bit까지도 효과적으로 적용 가능
하지만 MoE와 같이 엄청나게 큰 모델의 경우 이정도의 압축만으로는 실효적인 이득이 없음(결국 1 Node에서 처리할 수 없으므로..)
Ternary quantizing (3 values) works very well for MoE
매우 많은 수천개의 Experts로 구성되어 있고 이 Experts network만을 중점적으로 quantization하여도 전체적으로 큰 압축 효과를 달성할 수 있고
실질적으로 Inference 시점에 활성화 되는 Network 중 일부만이 압축된 것과 같으므로 Error를 최소화할 수 있을 것 (MoE는 주어진 입력에 따라 일정 Expert Network만 활성화)
MoE는 Pre-training / Finetuning 시 Token Dropping이라는 방식을 이용해 Regularization을 함, 따라서 Noise에 더 Robust함, 그래서 Quantization에도 더 Robust할 것임
Brief procedural description
Calibration data를 이용하여 activation에 대한 통계 정보를 수집,
수집된 정보를 이용 Experts를 quantization using GPTQ
Quatized weight를 custom dictionary scheme으로 인코딩
encoding metadata를 저장
full precision experts를 인코딩된 weight로 대체
결론적으로 Inference 시 이 custom dictionary scheme을 decoding 하는 단계가 추가됨
높은 성능의 LLM은 많은 컴퓨팅 자원을 필요로 함.
새로운 quantization 방식을 소개 GPTQ
175B parameters의 모델을 4GPU hours만으로 3 ~ 4 bit per weight으로 압축하며 이를 통해 Single GPU에서 추론을 가능하게함.
이러한 압축에도 정확도의 손실이 거의 없으며, 더 심한 압축에도 어느정도의 정확도를 보임을 확인
이렇게 얻은 압축된 모델은 3 ~ 4배의 비용 효율성을 보임
Approach
Accuracy의 손실 없이 Quantzation을 하기 위해 이를 최소화 하기 위한 Quantization ordering이 있었음 (OBQ 등)
하지만 대규모 모델의 경우 이러한 Ordering의 효과가 크지 않음을 확인하였음
Layer-wise quantization은 memory lazy-batch update를 가능하게 하여 memory 요구량을 감소시킴
Hessian Matrix를 통해 W의 변화에 따른 Output의 민감도를 구하고 이를 기반으로 quantization을 수행하여 accuracy의 손실을 최소화
모델의 규모와 학습 데이터의 증가로 Pre-trained Language Model은 학습된 언어의 의미 관계에 대한 Induction bias를 가지고 있으며 이에 의해 언어의 관계에 의해 나타나는 다시말해 언어의 Composition 규칙에 의해 드러나는 지식과 논리적 추론의 과정에 대한 Induction bias (귀납적으로 유도된 경향)
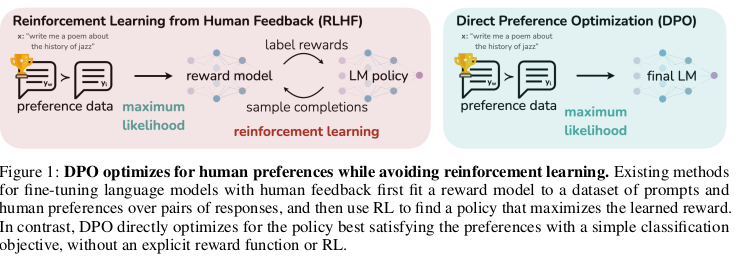
LLM의 Alignment를 위한 방법으로 RLHF(RLAIF)가 널리 사용되어 왔음
하지만 많은 노동력을 필요로하며 Preference dataset과 이를 이용한 Reward Model을 학습시키고 다시 이를 활용하여 RL을 해야하는 등 복잡하며 비용 집약적이다.
Approach
DPO는 Bradley-Terry Model이라는 Preference 모델을 도입
Preference의 비교를 Binary Classification으로 단순화 시킴
Ranking을 부여하는 기존 RLHF 방식보다 단순한 Annotation, 결과적으로 일관성을 얻기도 유리
Preference의 통계적 Representation을 위한 Reward Model을 없애고
Target Model의 Completion을 직접 Loss 함수에 활용할 수 있음
DPO는 Fully Differentiable, 즉, RL이 아니라 Fine-tuning 방식임 (RL은 개별 Trial의 명확한 Loss가 불분명한 경우 다수의 Trial의 결과의 전체 평가를 기준으로 Loss를 구하는 방식)
위에서 다룬 DPO를 이용 한단계 진일보한 테스트를 수행한 연구
이 Zephyr는 Mistral-7B를 기반으로 Fine-tuning과 Alignment까지 모두 Distillation에 의해 수행한 시도로써 의미가 있다.
Approach
dSFT (distlled Supervised Fine-tuning)
GPT-3.5-turbo의 multi-turn 데이터로 구성된 UltraChat Dataset을 활용
각종 오류와 낮은 품질의 데이터를 제거하고 200K샘플을 확보
이를 이용하여 SFT을 적용
dDPO (distilled DPO)
4종의 LLM의 답변으로 구성된 UltraFeedback 데이터를 활용
GPT-4에게 평가하도록 하여 Preference DPO를 위한 데이터를 구축 (GPT-4가 고른 최상의 답변을 Chosen으로, 그리고 나머지 3중 랜덤으로 Reject로 선택 구성)
이를 활용 DPO를 수행
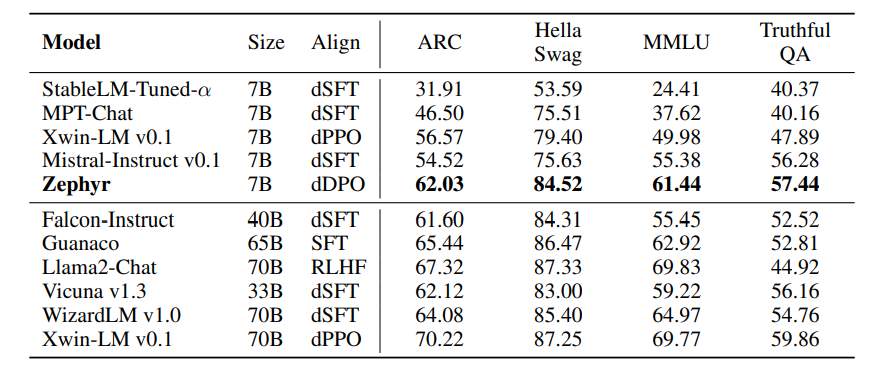
Result
Parameter가 더 큰 규모의 모델인 Falcon-Instruct (40B)나 Llama2 (70B) 대비 동등 혹은 우세
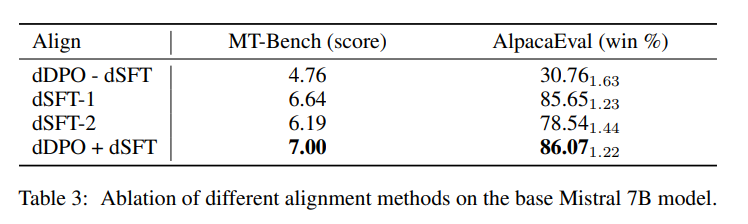
Ablation study
dSFT만 하였을 때 보다 dDPO를 함께 한 경우가 더 성능이 좋았음
추가적으로 dDPO의 Training Epoch을 증가시키면 Overfitting 하는 현상을 보임 (Perfect Match)
하지만 이러한 Overfitting이 MT-Bench 등을 볼 때 딱히 문제가 되지는 않았음 (MT-Bench가 오히려 증가함)
하지만 dSFT의 Epoch이 1보다 큰 경우 (오래 훈련 시킨 경우) 특이하게도 이러한 Overfitting이 문제가 되기 시작함
Implication
distillation은 Open Source 모델의 성능을 개선하는데 매우 효과적인 방식일 수 있음
생성 데이터와 이 생성데이터의 AI Feedback만으로도 AI의 Alignment가 가능함 (학습에 사람의 필요가 거의 없어짐, 이미 사람의 가치관을 학습한 LLM이 존재하므로)
Please enable JavaScript to view the comments powered by Disqus.